Compare Two Excel Sheets with Different Number of Rows and Find Differences using Python
Introduction
In this blog post, I will show you how to use Python to compare two Excel sheets and find their differences. This is particularly useful when you have a list of names and corresponding expected arrival dates, and you need to identify which cells have been changed after an update. 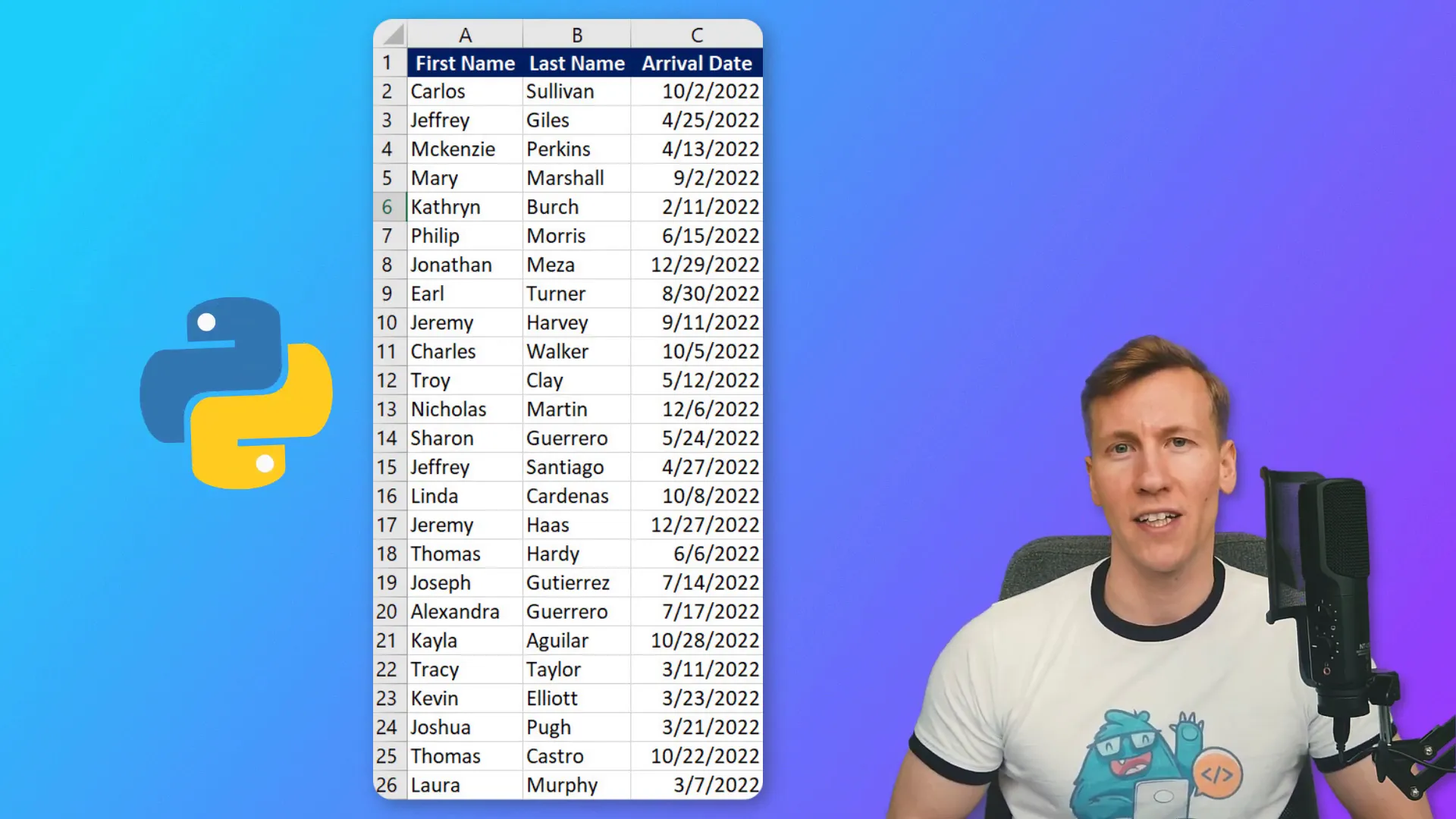
Install & load dependencies
First things first, we need to install the required dependencies. To manipulate Excel files, I will use pandas and xlwings. Additionally, pandas relies on the optional dependency openpyxl when working with Excel files. You can install all modules by opening your command prompt or terminal and running:
pip install openpyxl pandas xlwings
Once that’s done, I’ll import the necessary libraries:
import pandas as pd import xlwings as xw from pathlib import Path
Data with the same shape using pandas
Let’s start with comparing two datasets that have the same shape, meaning they have the same number of columns and rows. In my example, I have an initial spreadsheet and an updated version where only the values within each row might have been updated. 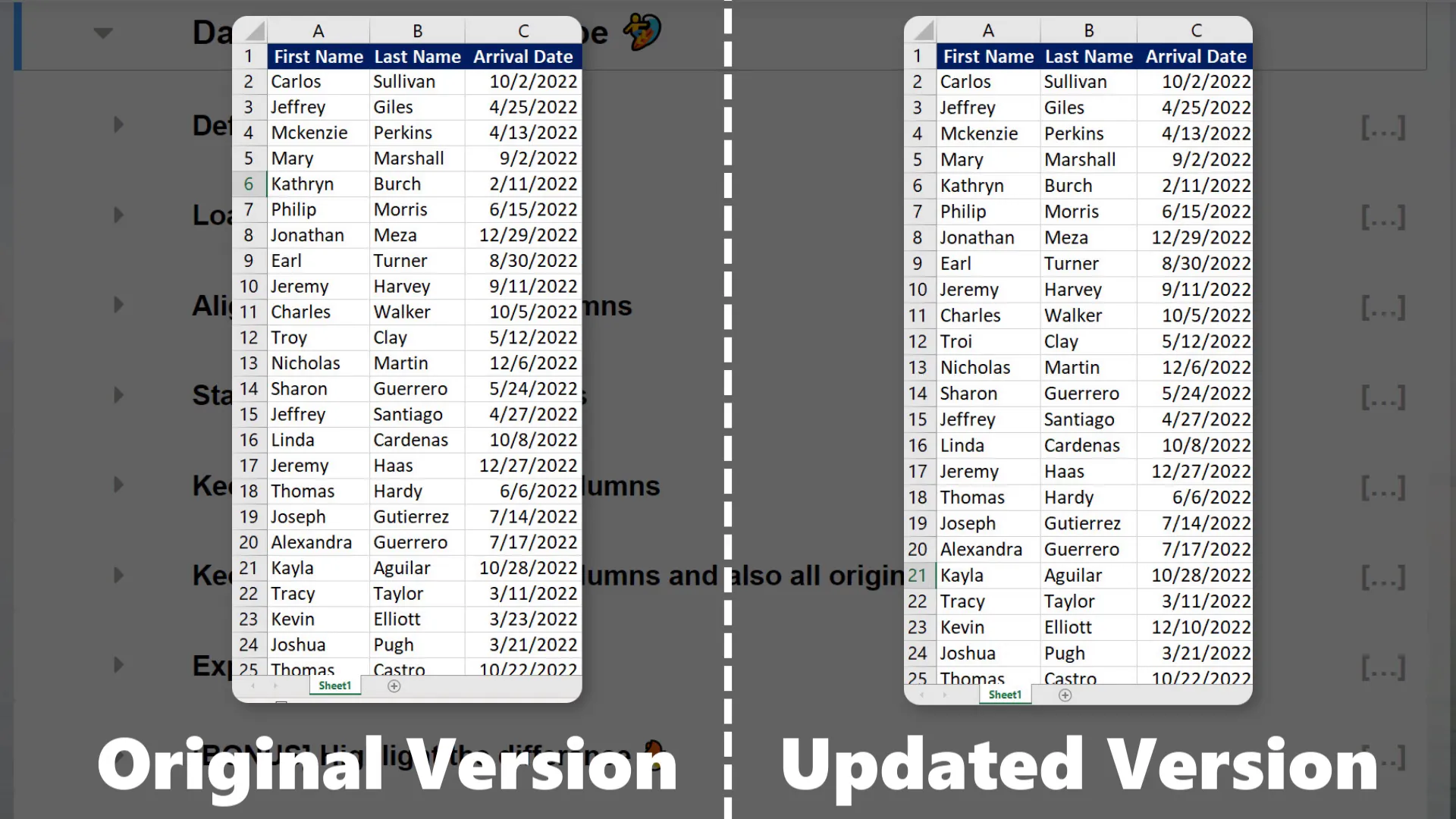 To define the file paths for both Excel files, I’ll use the pathlib module, creating a variable for the directory where the files are located. Next, I will bring the Excel data into a pandas DataFrame using:
To define the file paths for both Excel files, I’ll use the pathlib module, creating a variable for the directory where the files are located. Next, I will bring the Excel data into a pandas DataFrame using:
df1 = pd.read_excel('path_to_initial_file.xlsx')
df2 = pd.read_excel('path_to_updated_file.xlsx')
Now that I have both DataFrames, I can compare the data using the pandas compare method. This method can only compare identically-labelled DataFrame objects—meaning they must have the same row and column labels. 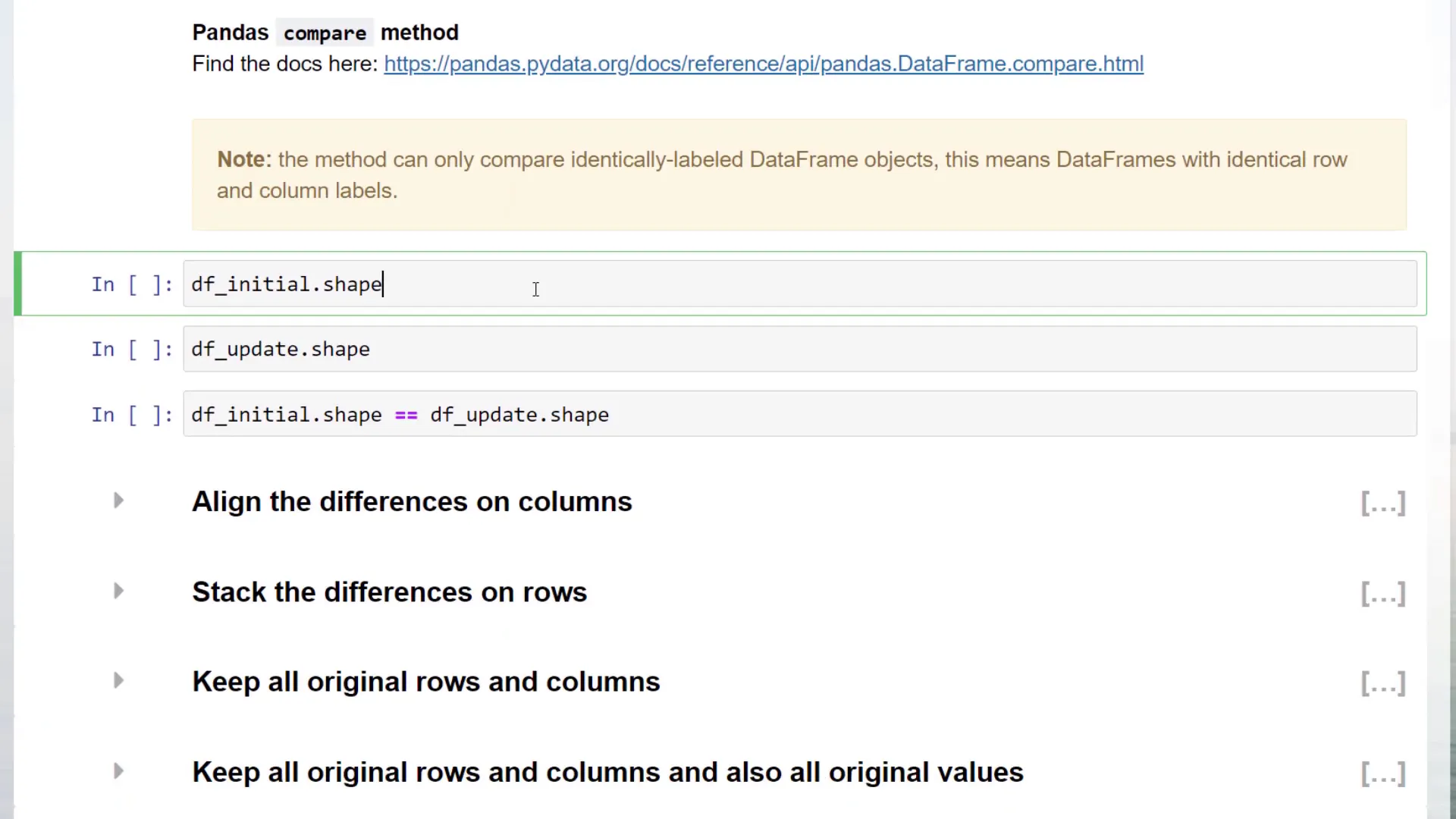 After running the comparison, pandas returns a DataFrame showing all the differences. For example, if the name “Troi” has been changed or some arrival dates have been updated, those changes will be highlighted.
After running the comparison, pandas returns a DataFrame showing all the differences. For example, if the name “Troi” has been changed or some arrival dates have been updated, those changes will be highlighted.
Data with the same shape using xlwings
In addition to pandas, I can also use xlwings to highlight differences directly in the Excel file. This involves creating a new Excel instance and opening both workbooks.
app = xw.App(visible=False)
wb1 = app.books.open('path_to_initial_file.xlsx')
wb2 = app.books.open('path_to_updated_file.xlsx')
Using xlwings, I can get the used range of the worksheet and iterate over each cell. If the values do not match, I can add a comment to the cell and change its background color to indicate a difference. 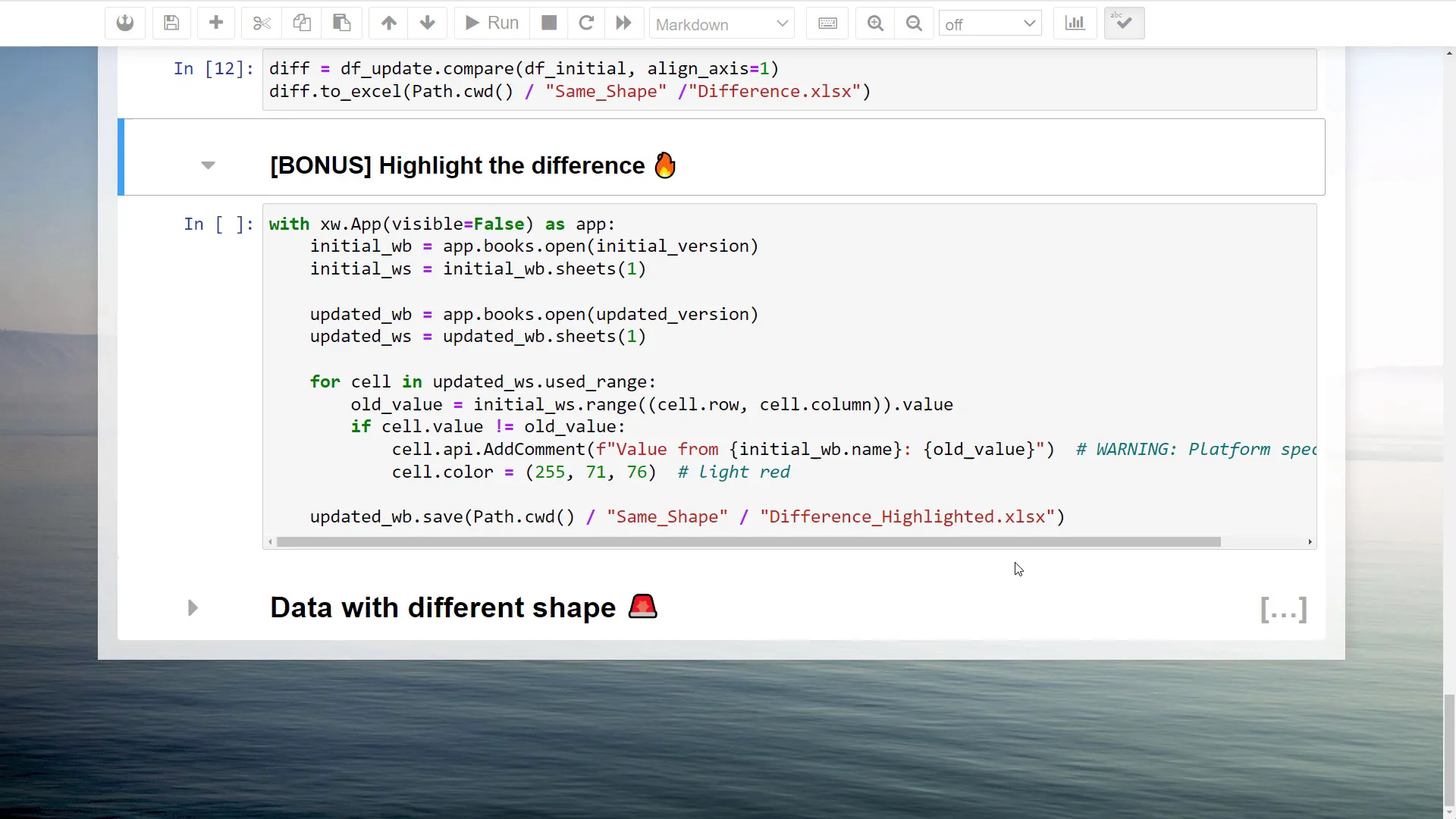 After executing this code, the updated workbook will have all the differences highlighted in red, along with comments showing the previous values.
After executing this code, the updated workbook will have all the differences highlighted in red, along with comments showing the previous values.
Data with different shape using pandas
Now, let’s move on to a more complicated example where the datasets have different numbers of rows. For this, I will merge the DataFrames instead of using the pandas compare method. To do this, I will reset the index of the updated DataFrame and perform an outer merge to keep all rows from both DataFrames:
merged_df = pd.merge(df1, df2, how='outer', indicator=True)
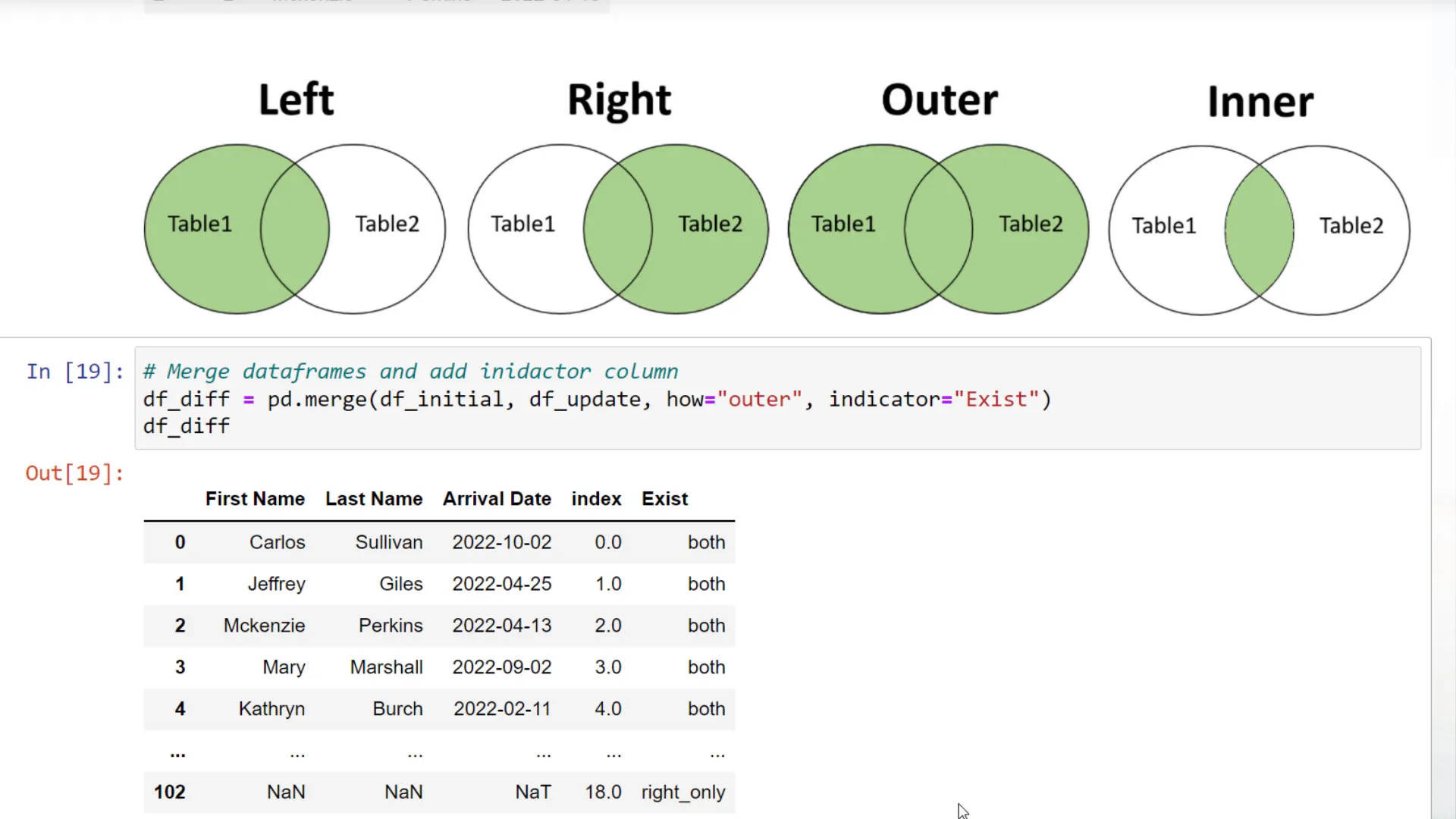 The resulting DataFrame will include an indicator column that shows whether the row exists in the left or right DataFrame or both. I can filter out the entries that exist in both DataFrames to show only the differences.
The resulting DataFrame will include an indicator column that shows whether the row exists in the left or right DataFrame or both. I can filter out the entries that exist in both DataFrames to show only the differences.
Highlight the difference using xlwings
Finally, I can use xlwings again to highlight the rows in the Excel sheet that contain differences. I will loop over the used range and apply a red background color to any row that has been changed. 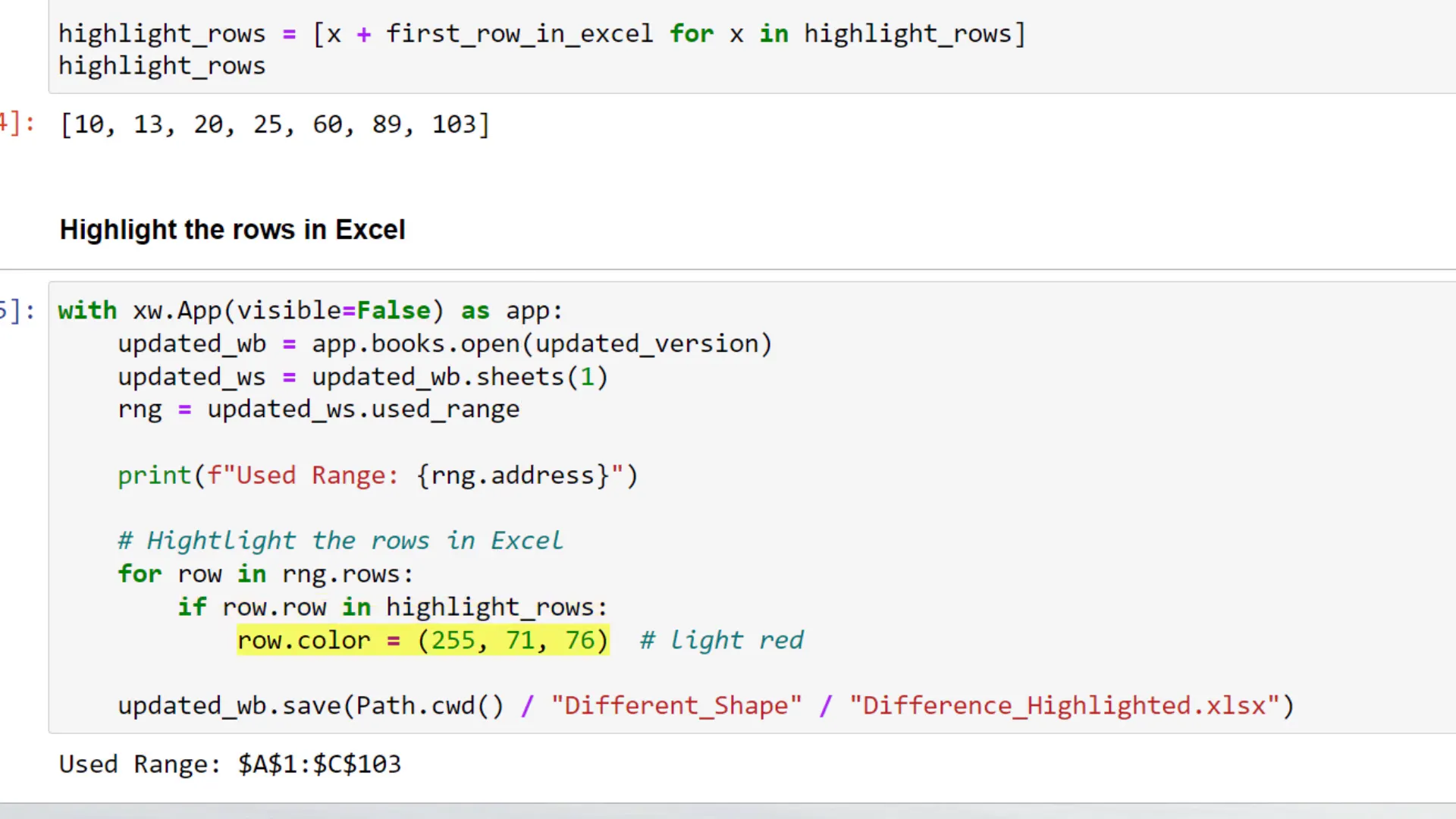 After executing the code, I will save the workbook as a new file and check the highlighted rows to easily identify the changes.
After executing the code, I will save the workbook as a new file and check the highlighted rows to easily identify the changes.
Summary
In this tutorial, I covered how to compare two Excel sheets using Python with both pandas and xlwings. You learned how to handle datasets with the same shape and how to manage differences when the datasets have different shapes. By highlighting differences directly in Excel, you can make your data comparison tasks much more efficient.