Replace your VLOOKUP. Use THIS instead!

Introduction
In the world of data manipulation, Excel’s VLOOKUP function has long been a go-to for merging datasets based on common identifiers. But what if I told you there’s a powerful alternative in Python that not only replicates VLOOKUP’s functionality but also offers enhanced flexibility? Let’s dive into how you can leverage Python, specifically the pandas library, to streamline your data merging process.
Traditional VLOOKUP
VLOOKUP is a function in Excel that allows users to look up a value in one column and return a corresponding value from another column. In this example, I have an ‘orders’ table containing order IDs, and I want to merge it with a ‘returns’ table that holds return reasons linked by those IDs. The ‘shipping’ table also provides shipping mode translations.
To consolidate this data, I initially use VLOOKUP to add return reasons and shipping mode numbers to my orders table. The formula looks something like this:
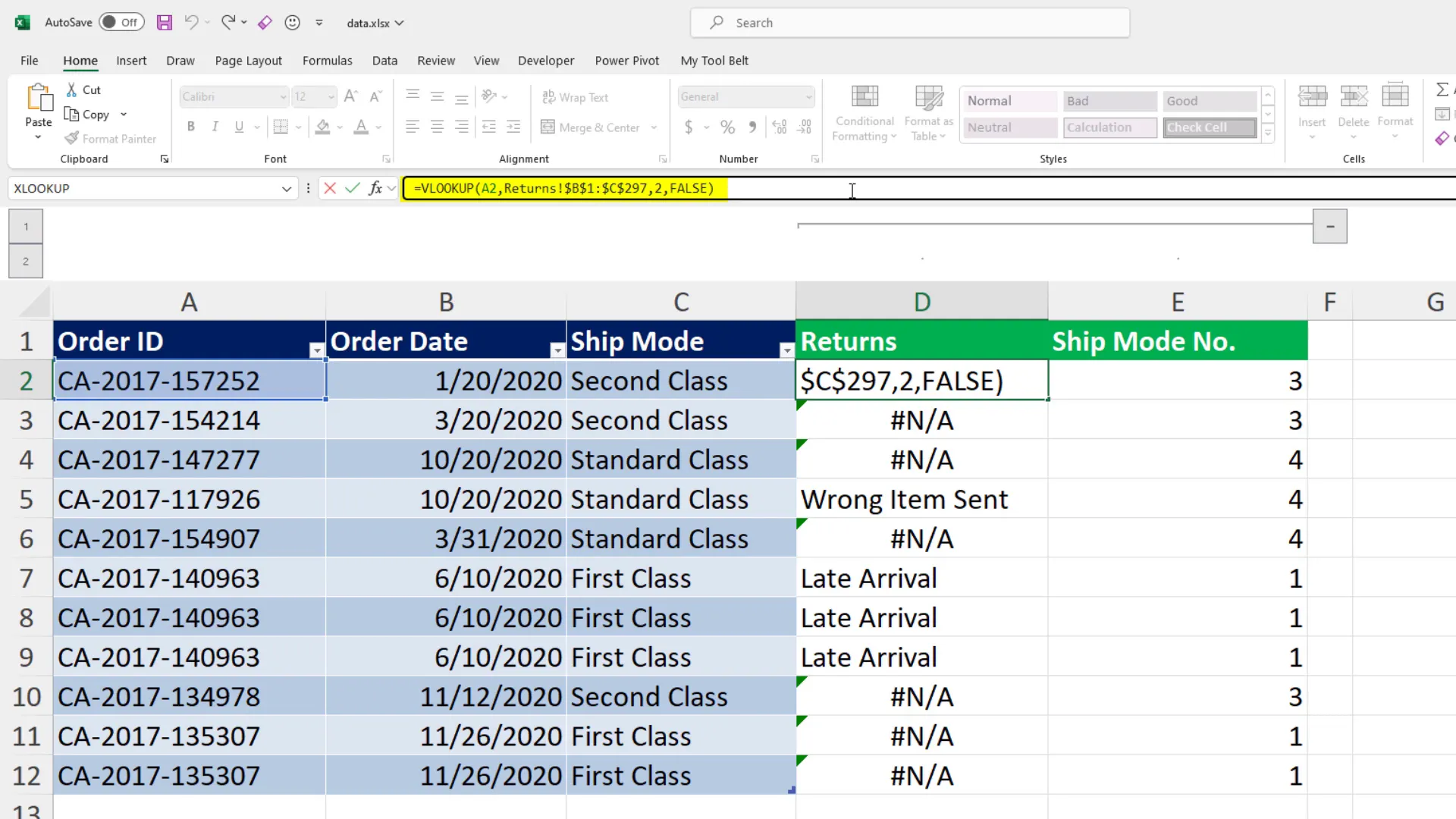
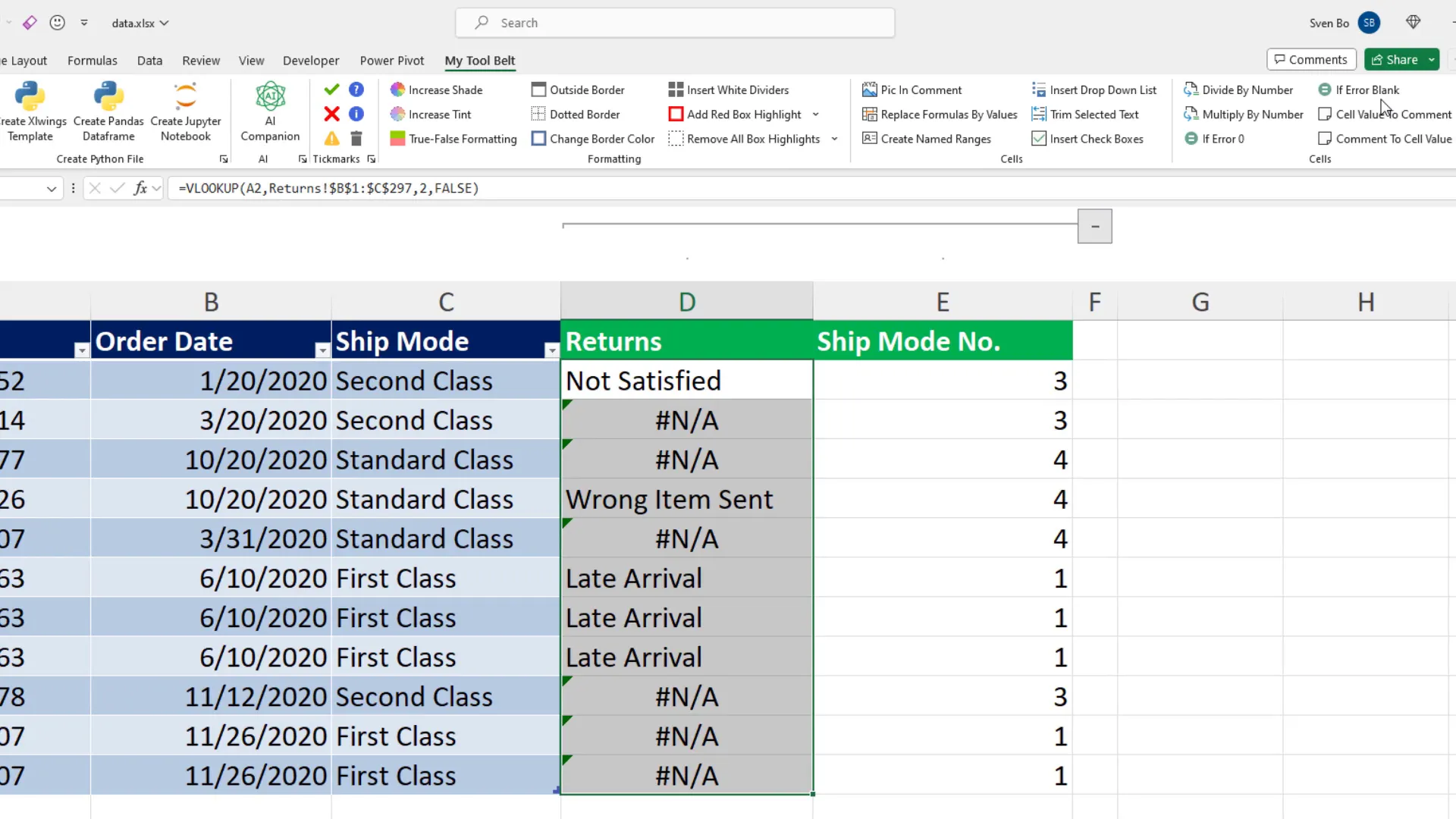
However, VLOOKUP has its limitations, particularly when it comes to flexibility in merging data. For instance, if an order ID isn’t found, VLOOKUP returns an error, which can complicate data analysis. To mitigate this, I often wrap my VLOOKUP formulas in an IFERROR function to handle missing values gracefully.
Python Alternative
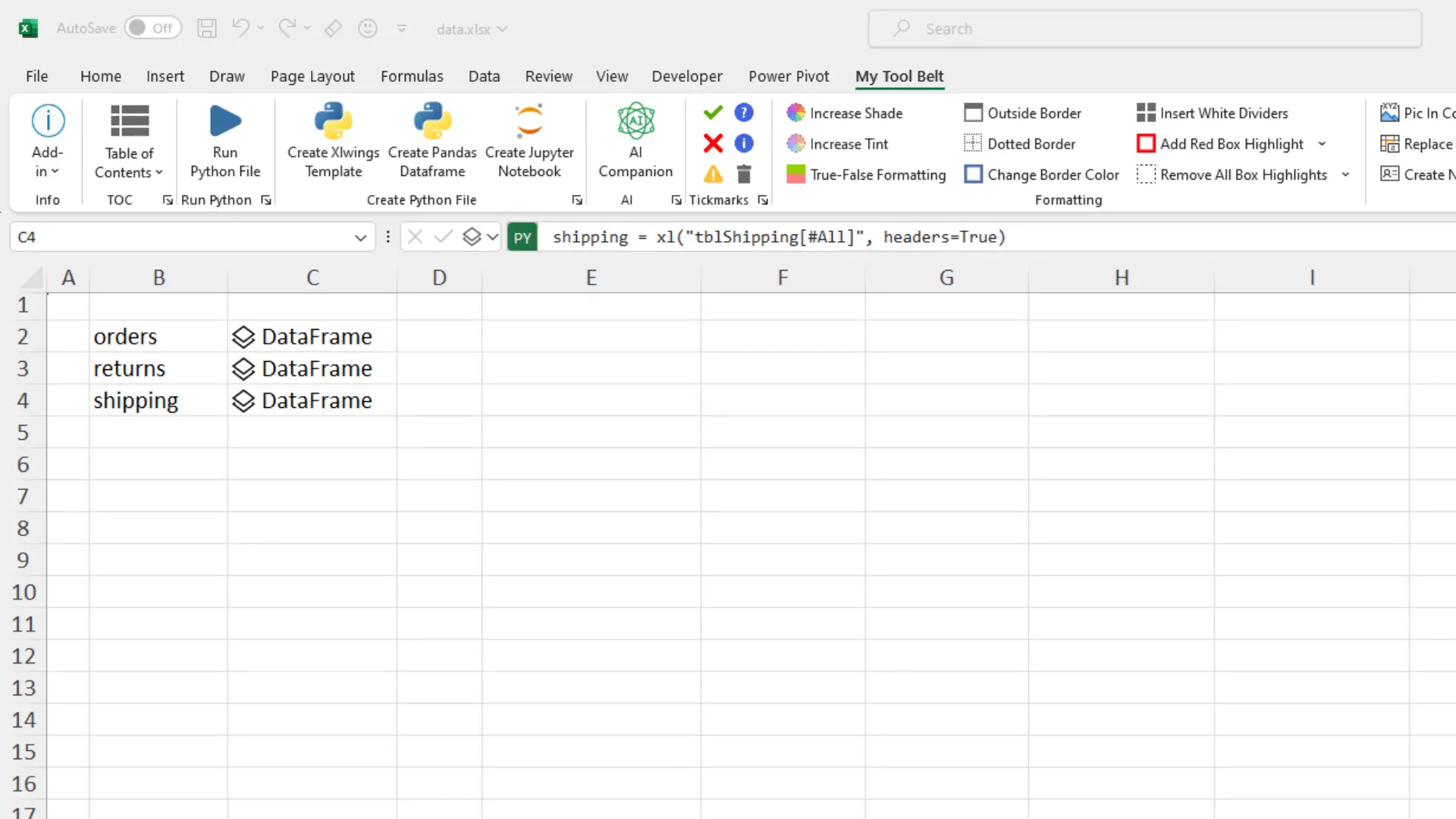
Now, let’s explore how to achieve the same results using Python. The first step is to import the data from each sheet into separate pandas dataframes. For the ‘orders’ table, I name the dataframe “orders”. I repeat this process for the ‘returns’ and ‘shipping’ tables, creating three dataframes: orders, returns, and shipping.
Next, I merge the ‘orders’ dataframe with the ‘returns’ dataframe using a left merge. This means I retain all rows from the ‘orders’ table while pulling in the corresponding return reasons from the ‘returns’ table based on the order ID.
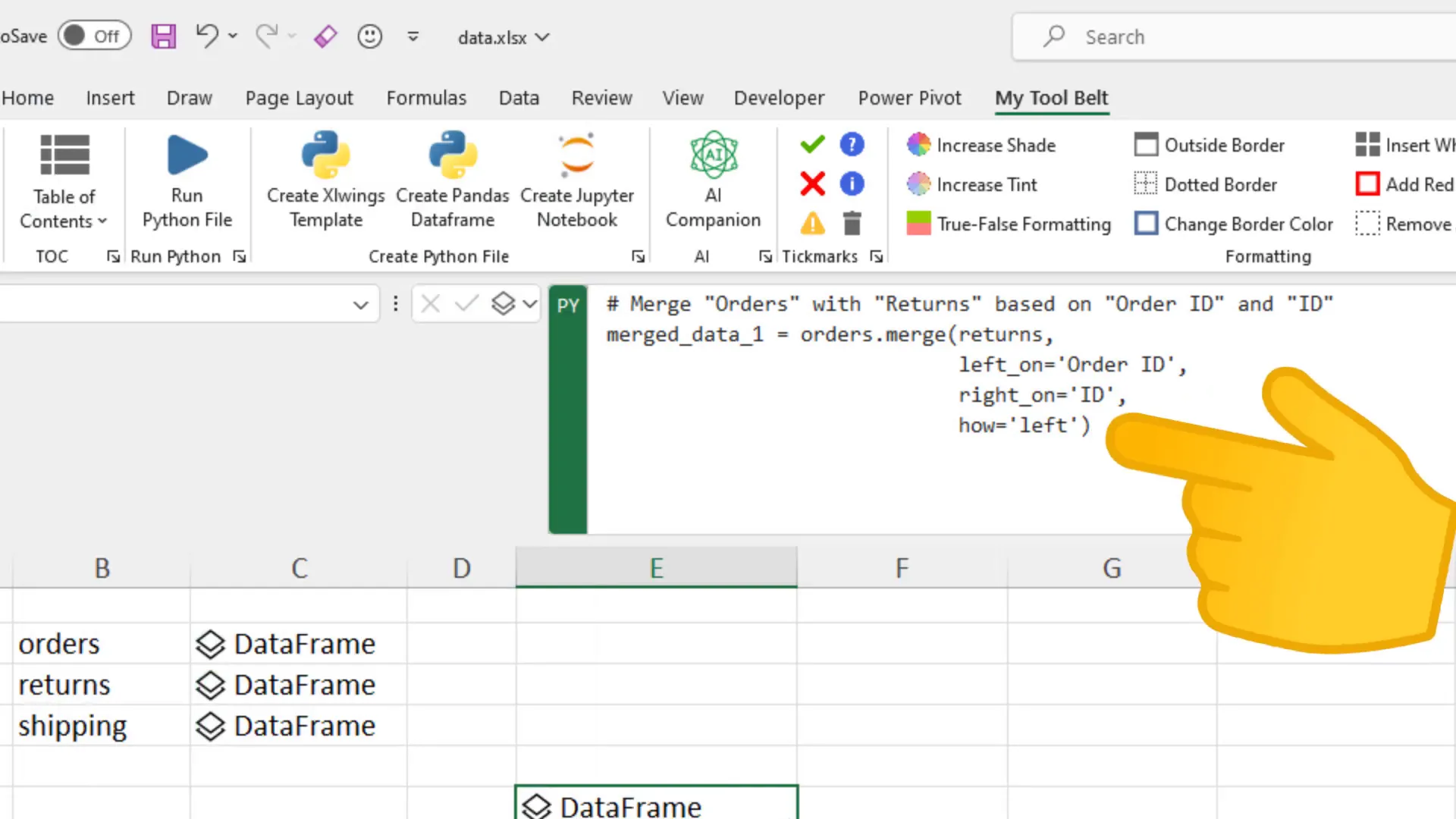
By using the pandas merge function, I can specify the columns to join on, even if they have different names, like “Order ID” in ‘orders’ and “ID” in ‘returns’. The left merge behaves similarly to VLOOKUP, but with the added benefit of not returning an error for missing values, which are instead filled with NaN.
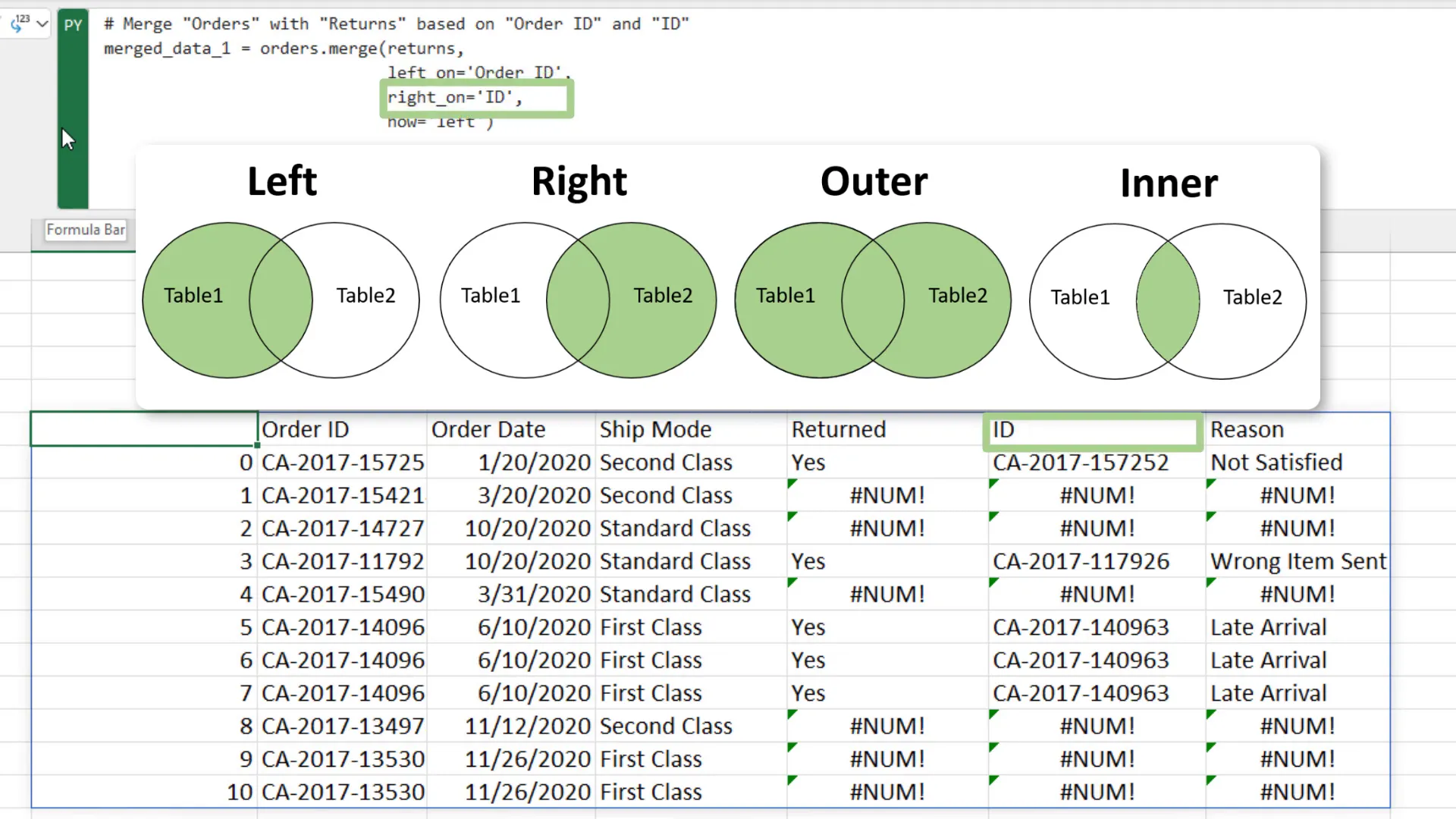
One of the advantages of using pandas is its flexibility with different types of merges. I can easily switch between left, right, outer, and inner merges by linking the merge type to a dropdown selection in my application. This allows for dynamic data analysis depending on specific needs.
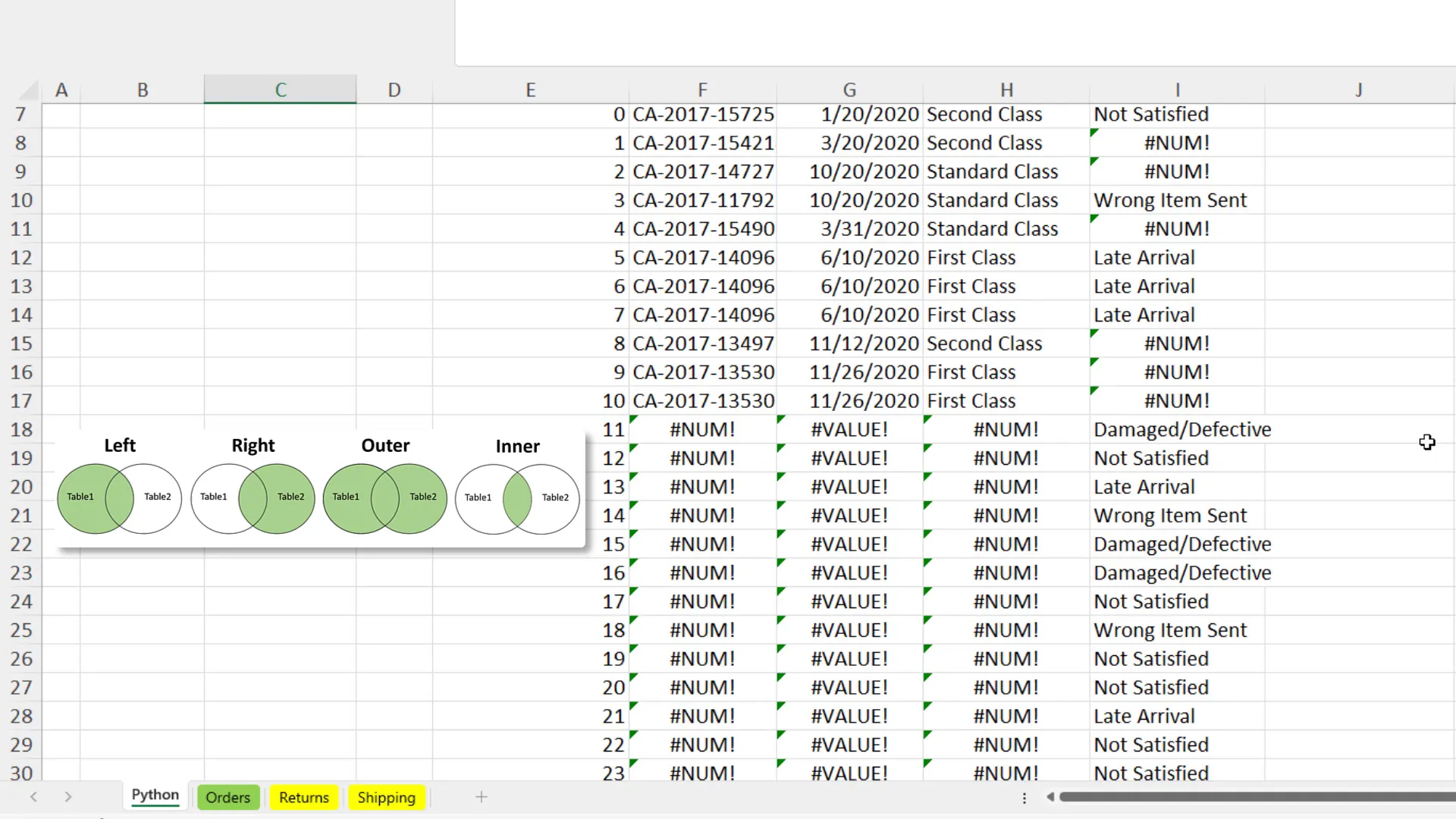
For example, a right merge will include all entries from the ‘returns’ table, while an outer merge combines rows from both tables. This is particularly useful for identifying Order IDs that have been returned but aren’t present in the orders table. An inner merge will show only the entries that match between both tables, further refining the data analysis process.
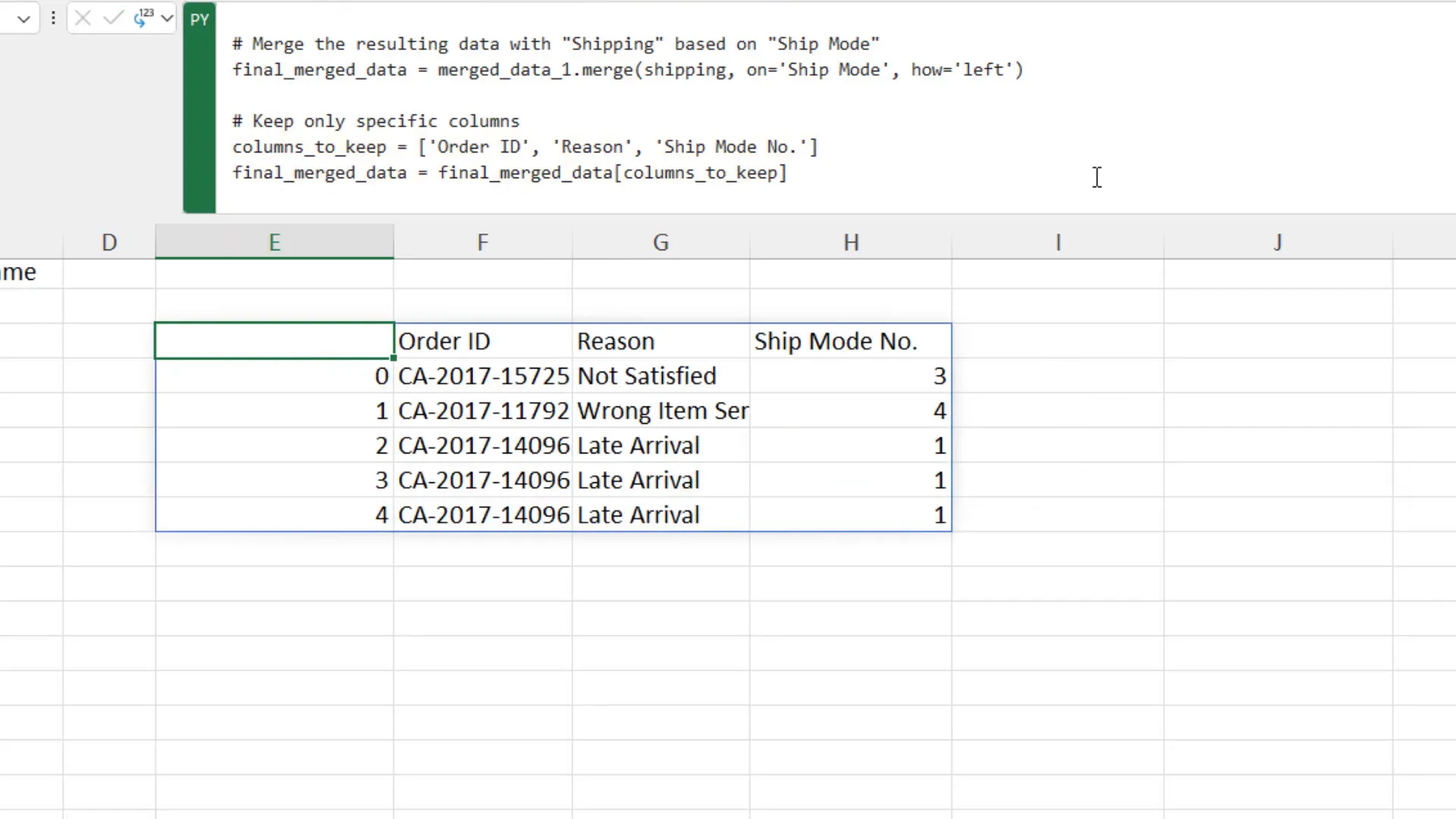
Lastly, to integrate the shipping data, I can perform another merge using the ‘Ship Mode’ column. This not only allows me to add the shipping mode number but also provides the option to filter the resulting dataframe to include only the columns I need, such as ‘Order ID’, ‘Reason’, and ‘Shipping Mode Number’.
Outro
In summary, while VLOOKUP is a useful tool in Excel for merging data, Python’s pandas library provides a more flexible and powerful alternative. By using pandas, I can perform various types of merges, handle missing values more effectively, and dynamically adjust my approach based on the data at hand.
So, whether you’re looking to streamline your data analysis or simply want to explore the capabilities of Python, learning to use pandas for data merging is a valuable skill that can enhance your data manipulation toolkit.