Python: How to Loop Through Folders and Subfolders

Introduction
In my folder, I have a couple of Excel files. Additionally, this folder also contains multiple subfolders with even more Excel files. Let us see how to iterate over each file in Python.
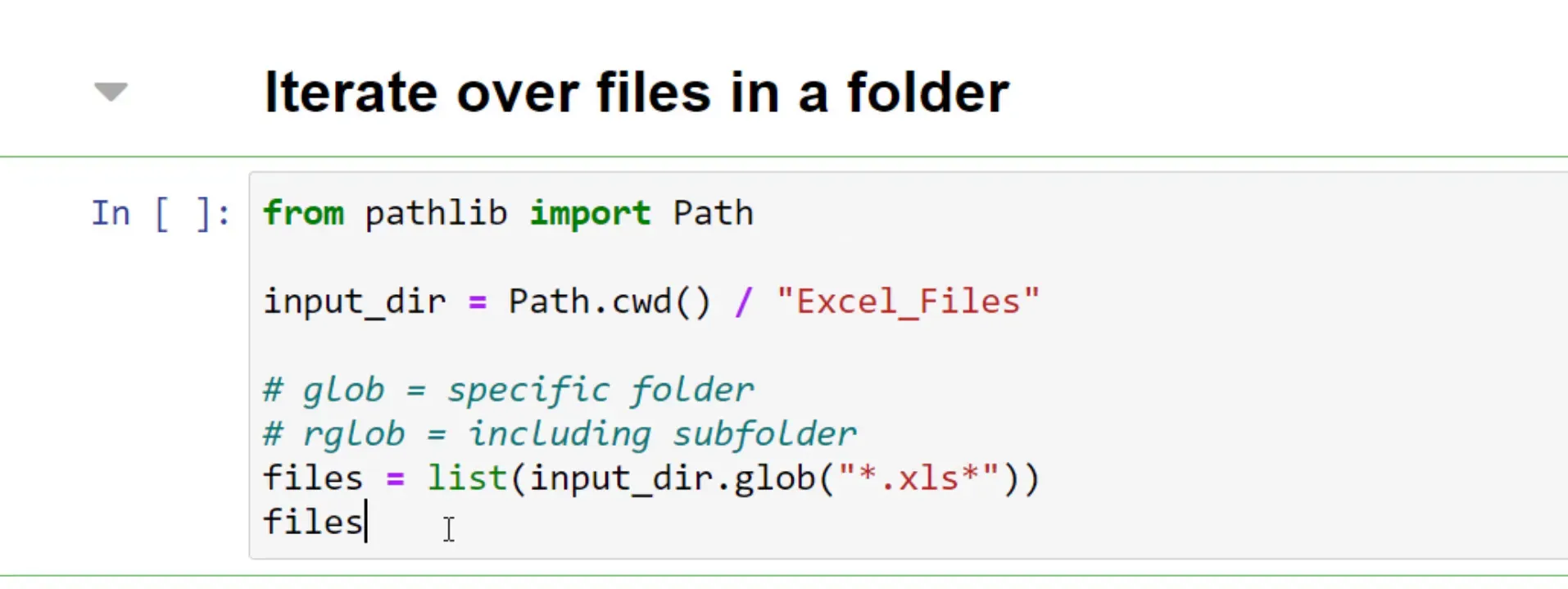
To achieve this, I prepared a Jupyter Notebook and I’m going to use the standard Python module Pathlib, which comes by default with Python 3.4 and above. After importing the library, I will specify our input directory. In my case, the folder with the Excel files is in the same directory as my Jupyter Notebook.
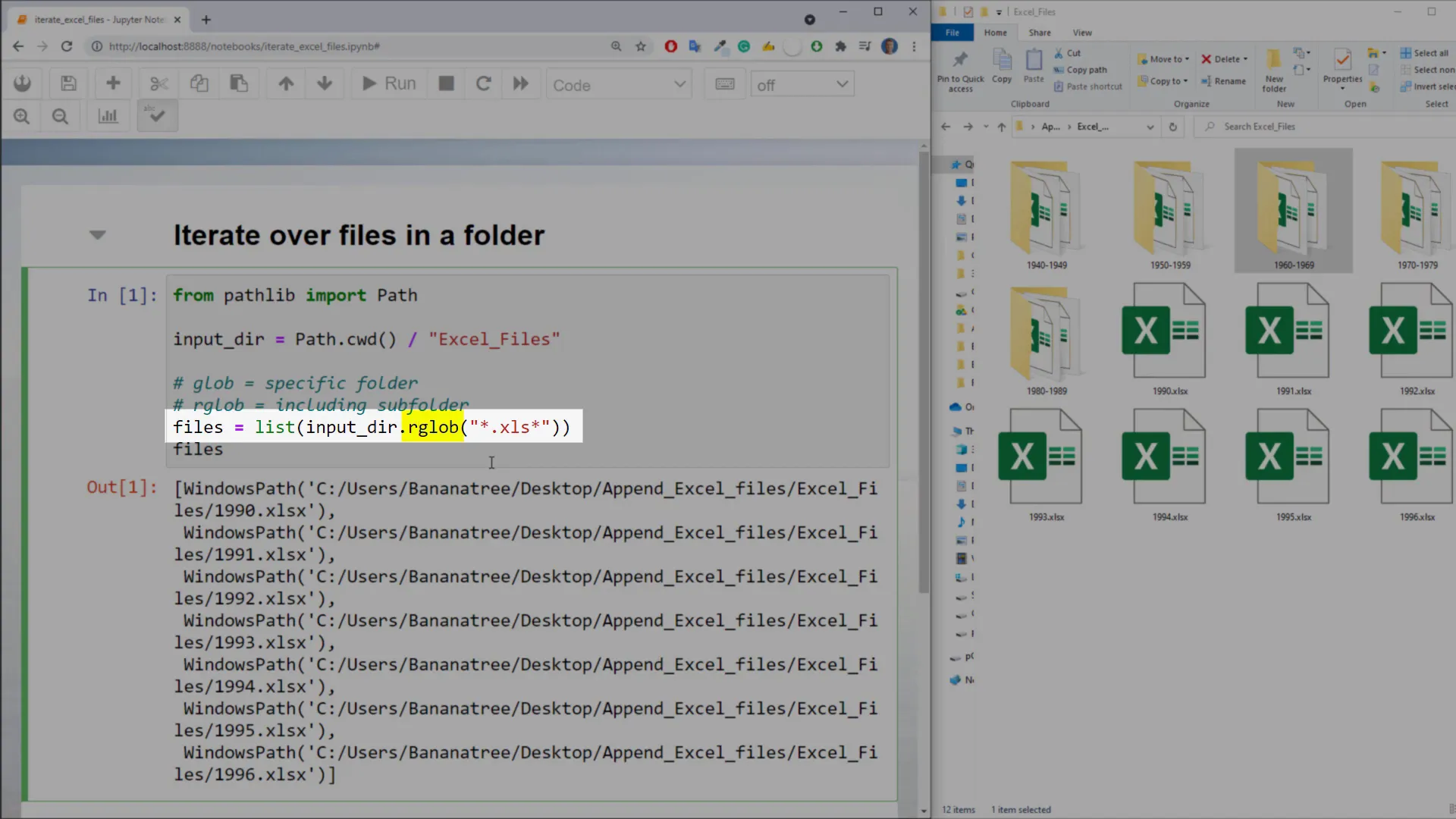
To iterate over each file, we only need one line of code. On our input folder, I will use glob and specify the pattern. In my case, I only want to return Excel files. I will then store each file path in a list called files. If I print out files, Python will return the seven Excel file paths. And that is all there is to it!
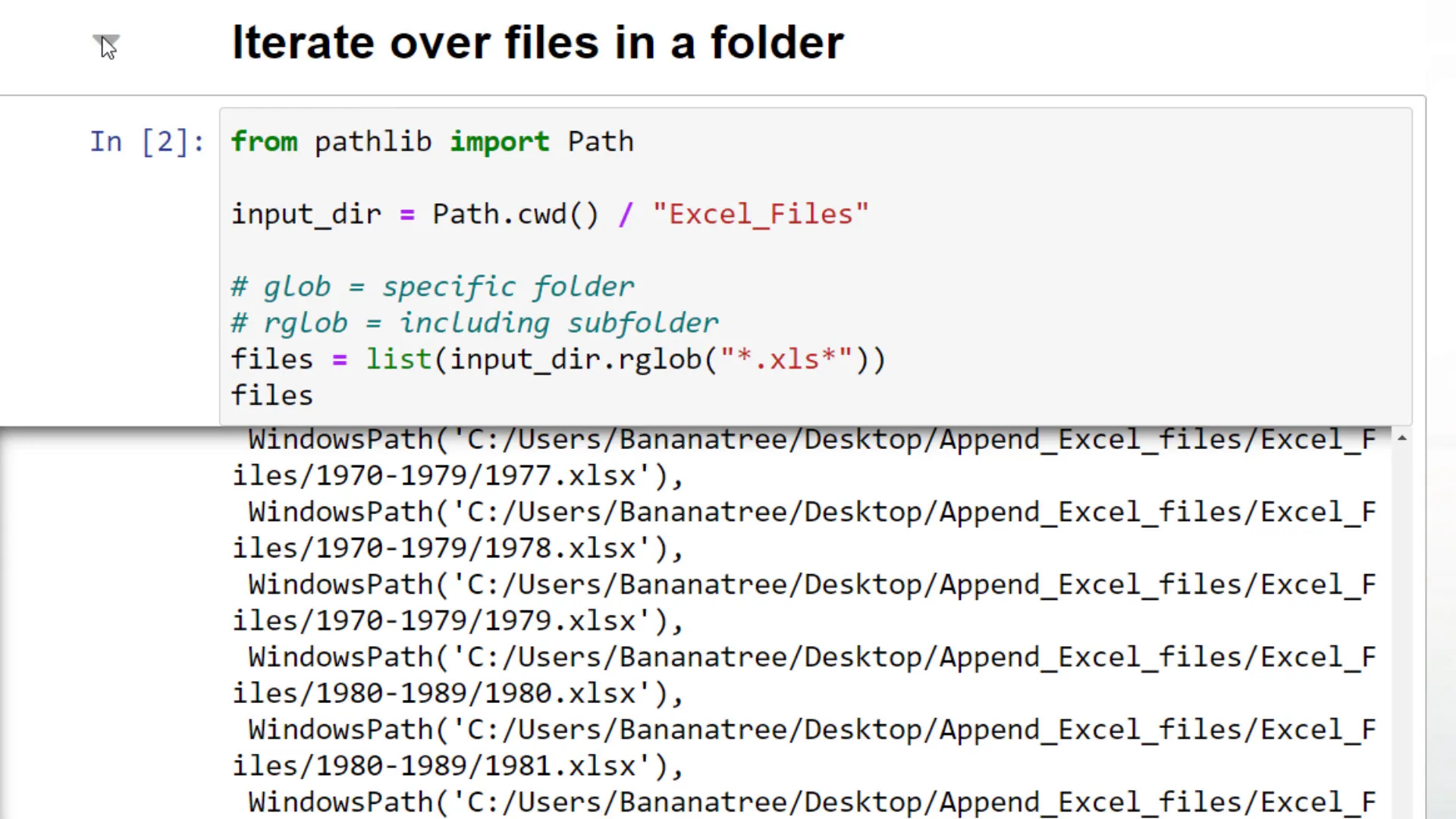
If you want to list all files, including those from the subfolders, you could use rglob. If I execute this cell, you will get back all Excel file paths.
Practical Use Cases
Now that you know how to list all files from any given directory, I will show you how to iterate over those files. For this, I have prepared some practical use cases. In my example, the format within each Excel file is the same, with only a slight difference. In the files from 1990 until 1996, the income column is missing.
Nonetheless, I intend now to merge all Excel workbooks into one master file. For this, I will use the pandas library. After importing pandas as pd, I will create an empty list called parts.
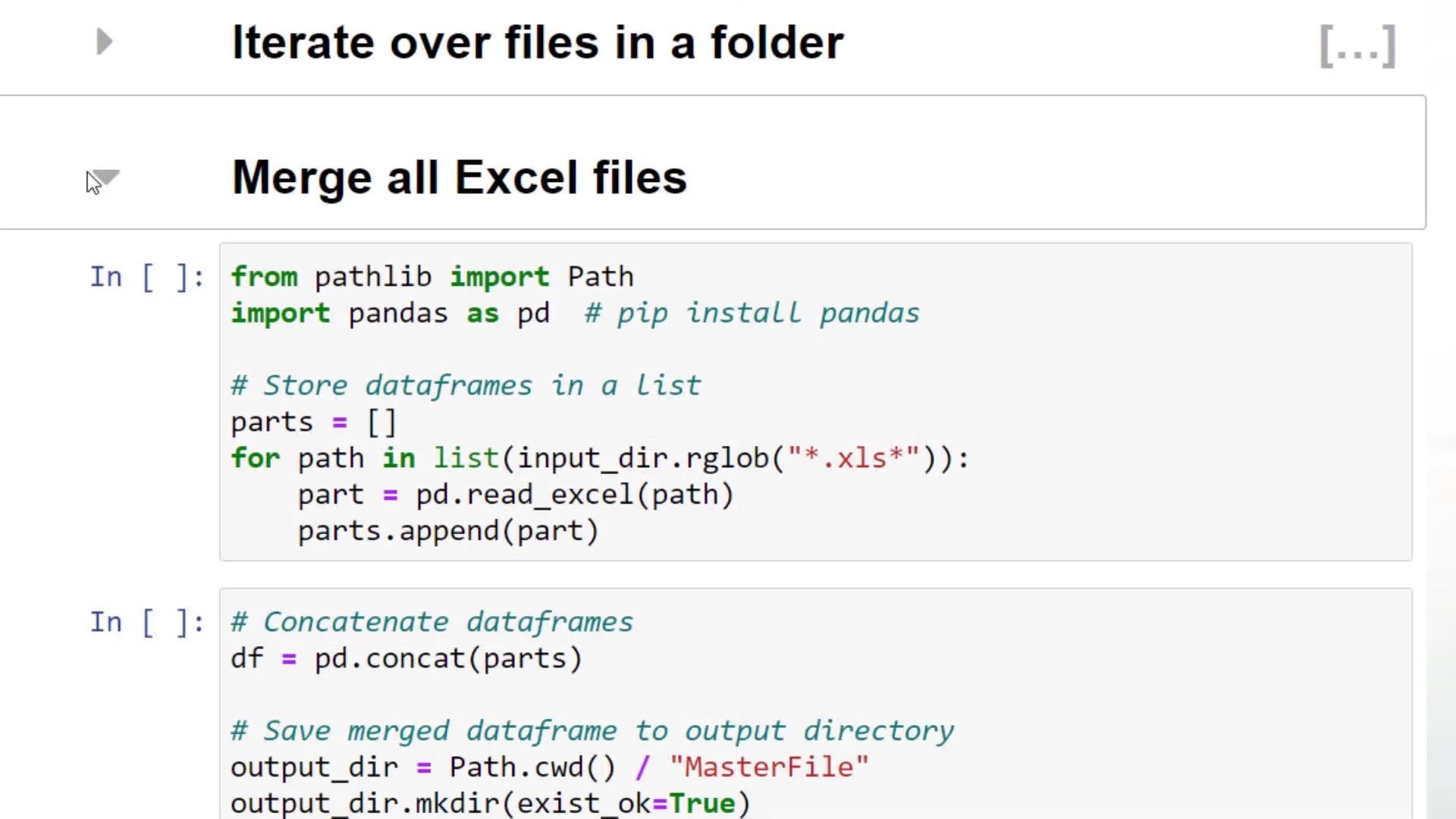
Then, I will iterate over each Excel workbook. For each Excel file, I will create a separate dataframe using pd.read_excel, before appending it to our list. Executing this line takes only a couple of seconds.
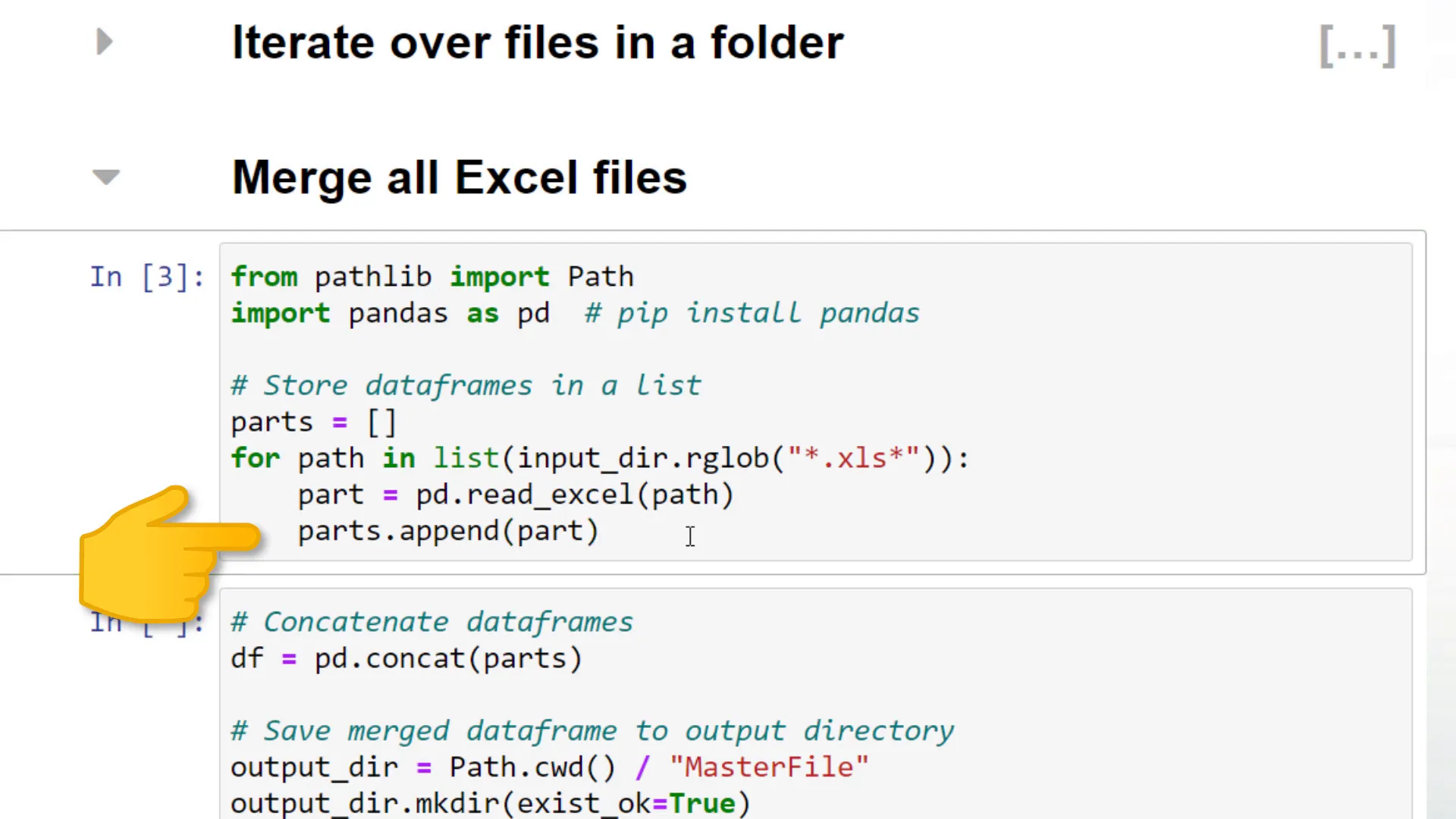
As the next step, I will merge the Excel files using pandas and the concatenate function. Once we have the merged dataframe, I will export it back to an Excel file.
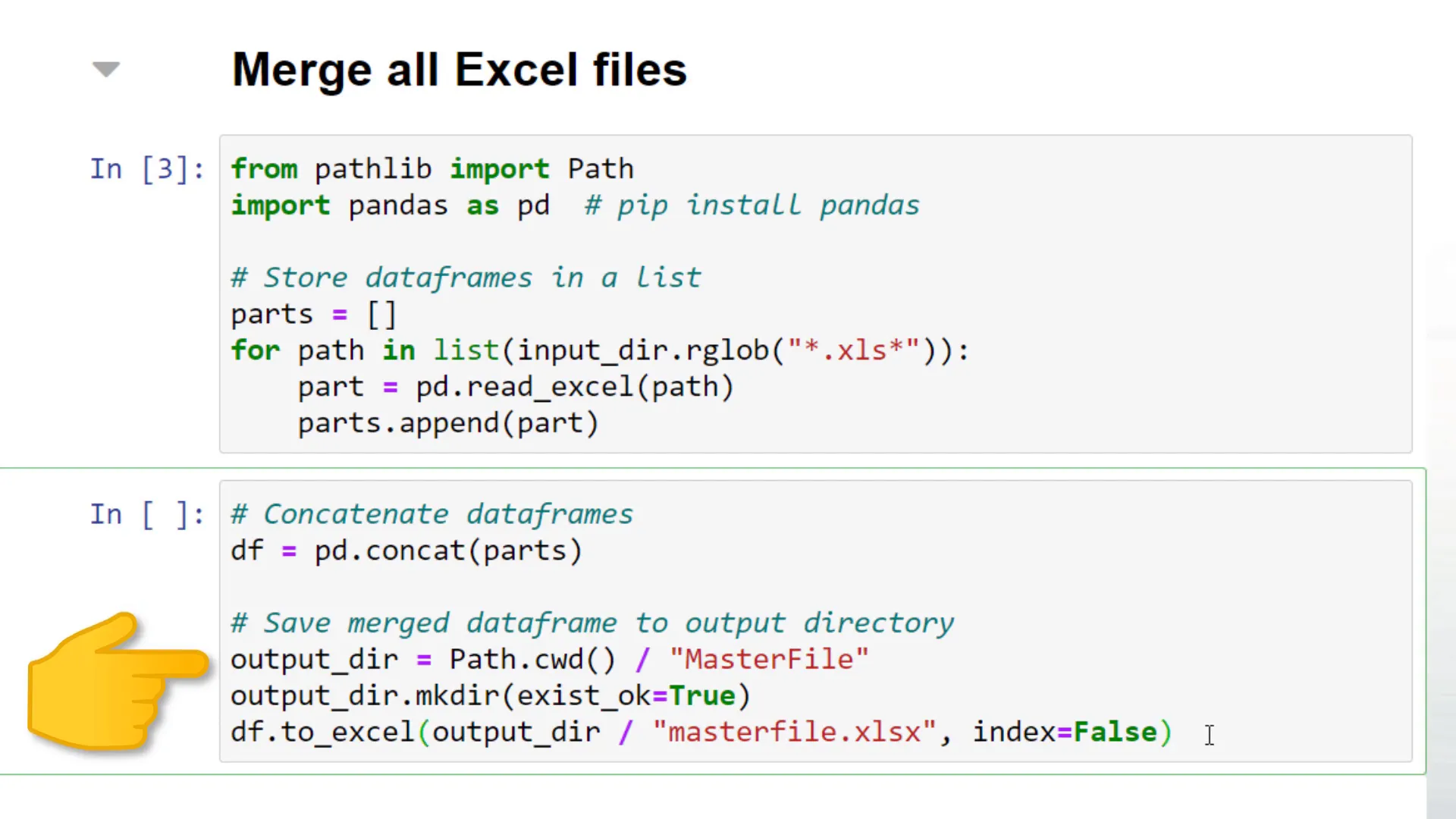
I would like to store it in a folder called Masterfile. If this folder does not exist yet, I will create it using pathlib’s mkdir function. As I do not want to include the index of the dataframe, I have set it to False.
After executing this line, we have our new folder with the master Excel file. If I open up this workbook, you will notice that all years are included. Pandas was also smart enough to include the income column.
If I filter out the blank row, you will see that only the years before 1990 are included. Doing something similar in VBA might be actually more cumbersome.
Changing Values in Excel Files
But perhaps instead of merging the files, you just want to change a particular cell. Instead of changing only one cell, you could also insert charts, change multiple values, add formulas, and so forth. Yet, for this example, I wanted to keep it simple.
Under the hood, pandas is using the openpyxl library, which allows you to read and write Excel files. So, let me import load_workbook from openpyxl. In our for loop, I will load each workbook into openpyxl.
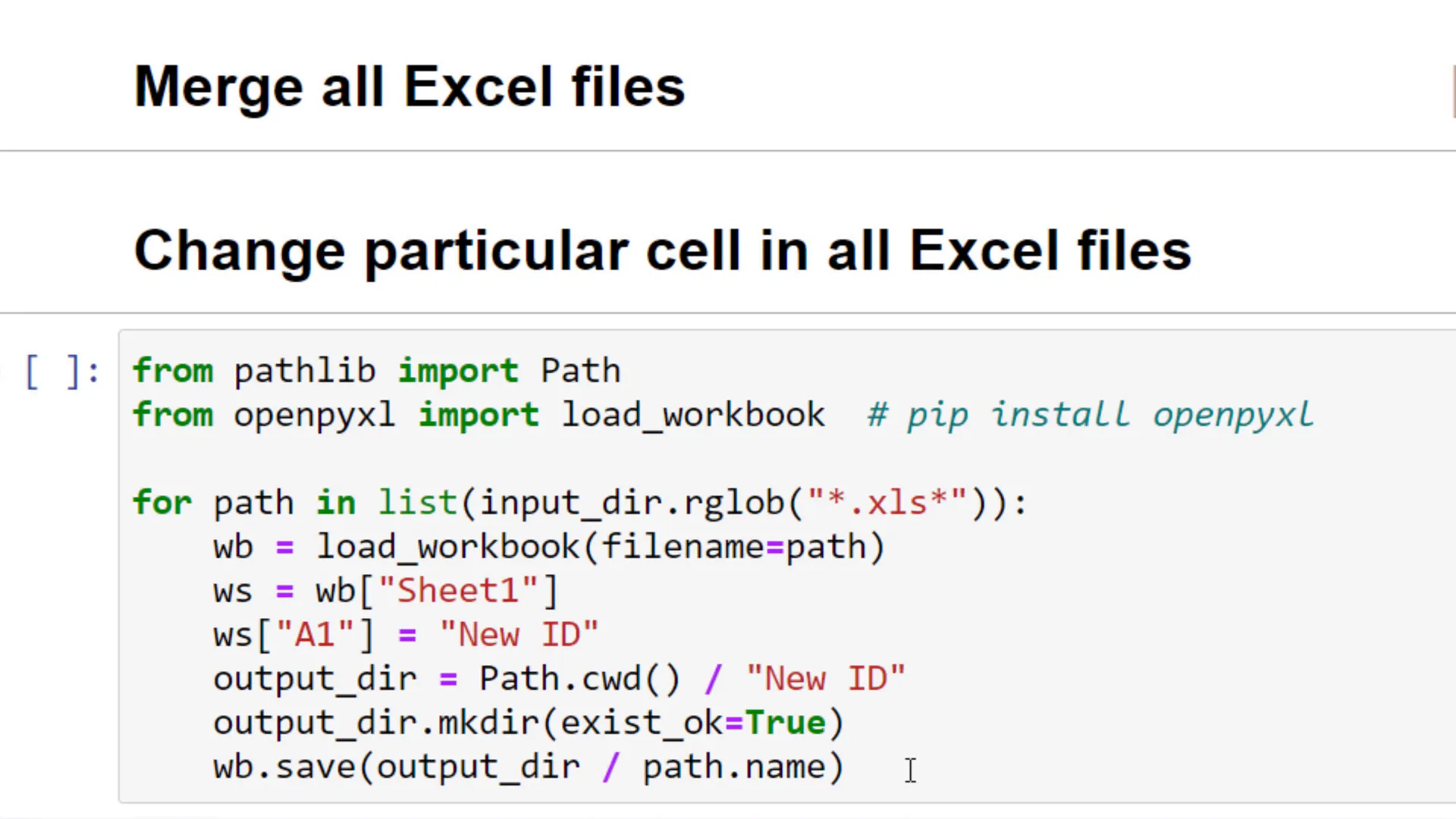
Within Sheet one, I would like to change the value in cell A1 to New ID. As before, I will save this file in a dedicated folder called New ID. After making any changes to the Excel workbook, you want to make sure to save the Excel file.
If I execute this cell, we will see the new directory. In this folder, we will now have all the Excel files, and within each Excel file, we will see that openpyxl changed cell A1 to New ID.
Ok, guys, and that is all for this tutorial. Thanks for reading!